
Data is both a currency just as valuable as the dollar and the backbone of any (successful) business today. For mobile-first businesses in particular, acquiring new users means managing a massive influx of complex data and identifying consistent growth opportunities, all while remaining cost-efficient. It’s no simple task, and one the modern data stack has attempted to revolutionize with a modular collection of analytics tools designed to scale.
What Does the Modern Data Stack Look Like?
The modern data stack describes the suite of technologies and tools used to aggregate, store, and process large amounts of data in a unified and affordable manner.
Where a technology stack helps software engineers build products through various programming languages and libraries, a data stack aims to drive data-informed decision-making across an entire business through streamlined data infrastructure.
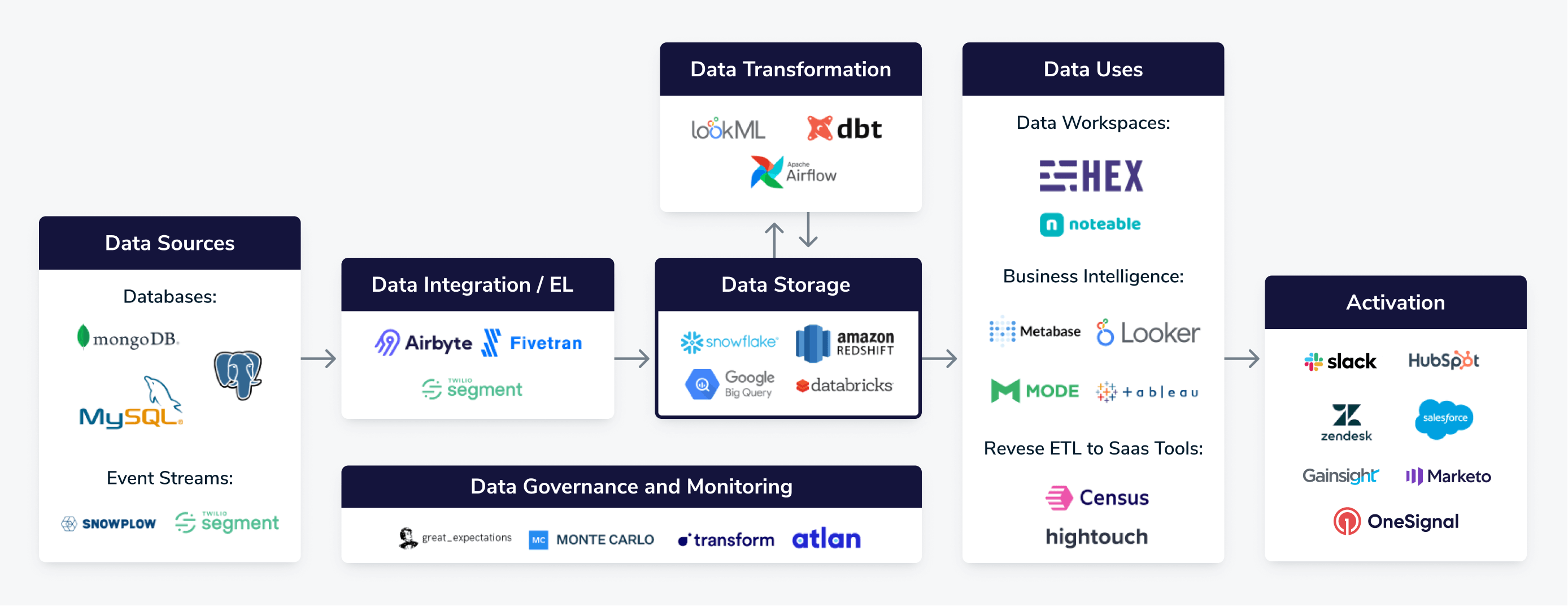
The oversimplified version?
Mass, unorganized data goes in → actionable, profitable insights come out.
The Modern Data Stack vs. The Traditional Data Stack
Now, just because something is new doesn’t always mean it’s an improvement. There are powerful arguments on both sides that tackle whether or not the modern data stack is a necessary deconstruction of traditional data management or merely an overly complicated smorgasbord of integrations.
First, let’s cover the ways in which the modern data stack attempts to usurp the all-in-one data solutions of yesterday. The key differences between a modern data stack and a traditional data stack involve flexibility and self-serve solutions. These are the most significant ways modern data stacks have evolved beyond the traditional data stacks of the past.
Scalability
Traditional data stacks typically use on-premises infrastructure and proprietary software solutions, limiting their scalability due to hardware constraints and rigid architectures. Scaling up requires significant investments and infrastructure changes.
In contrast, modern data stacks leverage cloud-based infrastructure, open-source software, and other scalable technologies to handle large volumes of data and more effortlessly integrate with existing infrastructures.
Data Variety
Traditional data stacks primarily focus on structured data, typically coming from relational databases and structured enterprise systems. Examples of structured data include customer information, sales transactions, and inventory data.
Conversely, modern data stacks are built to handle a wide variety of data types, including unstructured and semi-structured data such as social media posts, sensor data, logs, and multimedia content. They incorporate data lakes and NoSQL databases that accommodate diverse data formats. They also make use of distributed computing frameworks, data lakes, and NoSQL databases to provide a scalable and cost-effective solution for storing diverse data types
Real-time Processing
Traditional data stacks often operate on a batch processing model, where data is processed in periodic intervals. Real-time or near real-time data processing is challenging to achieve in traditional stacks.
Modern data stacks, on the other hand, embrace real-time and streaming data processing capabilities. They leverage technologies like Apache Kafka, Apache Flink, or Apache Spark Streaming to process data as it arrives.
Real-time processing offers significant benefits within the modern data stack, empowering businesses to make timely decisions, gain faster insights, enhance customer experiences, and enable continuous monitoring across data-driven applications.
Cost and Maintenance
Traditional data stacks require significant upfront investments in hardware, software licenses, and maintenance. Organizations are responsible for managing infrastructure, ensuring high availability, and performing regular updates and maintenance.
One of the largest differences and most impactful advantages of a modern data stack is its ability to offer a more cost-effective and agile approach. Cloud-based solutions provide pay-as-you-go pricing models, eliminating the need for extensive hardware investments. The cloud provider takes care of infrastructure management, updates, and maintenance, allowing organizations to focus on data analysis and insights.
Flexibility and Agility
Traditional data stacks are often rigid and less adaptable to changing business needs. Upgrading or introducing new technologies can be time-consuming and complex.
Modern data stacks prioritize flexibility and agility. They allow organizations to easily integrate new data sources, experiment with different tools and technologies, and quickly scale or pivot based on evolving requirements. Modern data stacks often employ a modular architecture that allows for easy integration and swapping of components, so companies can adopt best-of-breed solutions for each component of the data stack.
Data Democratization
Traditional data stacks often require specialized technical expertise to access and analyze data. Additionally, traditional data stacks often have slow iteration and development cycles, making it challenging to adapt quickly to changing business needs. Introducing new data sources, implementing changes to data models, or developing new reports and dashboards can involve lengthy development and deployment cycles. This hampers the ability to respond rapidly to evolving data requirements and limits the agility necessary for data democratization.
Modern data stacks emphasize data democratization, enabling self-service analytics and empowering users across the organization to access and analyze data. User-friendly data visualization and business intelligence tools make it easier for non-technical users to explore data and gain insights.
Modern data stacks are built for today’s need for speed. By embracing self-service analytics tools, advanced visualization capabilities, centralized data access, and providing education and training opportunities, modern data stacks empower users across entire organizations to explore and derive insights from data. This, in theory, fosters a data-driven culture and promotes more informed decision-making at all levels of the organization.
How Did the Modern Data Stack Evolve?
Origins of the modern data stack can be traced back to the early 2010s with the rise of high-volume data commoditization. During this time, two very important things transpired that allowed for an evolution from traditional stacks.
The first was the mass adoption of cloud computing, which enabled data to be accessed and processed from anywhere in the world. Cloud computing platforms, such as Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform, provide scalable and elastic infrastructure. This means that organizations can easily scale their data operations up or down based on demand, without having to invest in and manage on-premises hardware. These factors massively accelerated the adoption of modern data stacks.
The second factor that gave way to modern data stacks was the shift from ETL (Extract, Transform, Load) to ELT (Extract, Load, Transform) analysis workflows. Without going into excessive detail, ELT allows organizations to handle large volumes and diverse types of data by leveraging distributed storage and computing frameworks. Additionally, ELT's cost-effectiveness and compatibility with modern data architectures, such as data lakes and cloud computing, make it a compelling choice for organizations aiming to leverage the full potential of their data in a rapidly evolving data landscape.
Modern Data Stack Criticisms
For every diehard modern data stack evangelical, there is a data realist patiently waiting to tell you why this model is a recipe for inefficiency, higher spending, and a scaling nightmare.
The argument against this hyper-modularized data management model boils down to avoiding needlessly complex silos without proper upfront infrastructure. The result? A seemingly faster process with more moving parts to fail. Why have an engine with 24 pistons when six or eight get the job done more efficiently? This wouldn’t be a proper data stack discussion if we didn’t explore the other side of the coin.
In short, modern data stack detractors have adopted the stance that, “Just because you can, doesn’t mean you should.”
Potential Downsides of the Modern Data Stack
Isolation
The main weakness of the modern data stack may lie within its perceived strengths: modular control and the involvement of multiple data solutions. This structure can, unfortunately, lead to isolated pipelines that solve a single problem for a single particular business partner or product manager, but eventually fall into disrepair when no one has a use for them anymore. Because of this, data loses most of its value.
At its core, data should be a network, where entities relate, communicate, and interface with each other — a software engineer and data analyst should both be able to answer the same questions about a shared data network. One of the larger complaints with the modern data stack is the lack of communication between data producers and data consumers in multiple organizations working together. Sometimes, these different entities may not even know the other side exists. If both sides can’t easily answer the question, “How is your data being used in the company?”, you have a problem. Data will not be as fundamentally useful if every part of the machine isn’t synchronized.
On a more logistical note, different entities in a modern data stack are often named, organized, or structured completely differently than one another, leading to more tables, more computing, and more mess down the road. The modern data stack has garnered a reputation amongst some as a shiny solution that sacrifices quality for speed by “kicking the can” down the data assembly line.
Misplaced Confidence
Access to the right information is one thing, but scaling businesses require real expertise to interpret and unlock it. Although the modern data stack has enabled a new cohort of business-data hybrid roles to step in and make new contributions, these managers run the risk of developing a false sense of security simply because they’re overseeing an infrastructure with more moving pieces.
The mentality of “buy infrastructure first, confront problems later” leads to blindly using human middleware as a solution to challenges that require nuanced expertise. These hybrid roles are bogged down most of the time and not participating in any data engineering work. It becomes easier and easier to see, especially with an economic downturn, why some businesses are rethinking their strategies.
Many claim that what started as an earnest approach to adapting to cloud-based data has morphed into the blind-faith promotion of different technologies…for the sake of different technologies.
With investor dollar signs floating through the air like the cartoon scent of a freshly baked pie, it’s no wonder why speedy adoption and larger teams can become so lusted after. However, there is a growing school of thought that claims the modern data stack is packed with lots of features, lots of buzz, and not much else.
Fragmentation = An Enterprise-Unfriendly Approach
A common trap many businesses find themselves in is thinking they can put in place a fragmented infrastructure, try to organize it into an enterprise data model, THEN create value. This way of thinking runs contrary to all other common-sense scaling strategies. Critics of the modern data stack claim that, in reality, it’s not very modern at all — and that rather than being a “stack,” it represents more of a loosely connected family of tools.
The modern data stack began as a valuable model to add modular solutions supporting the implementation of warehousing, ELT, and data visualization tools to help bring data management into the modern era. Yes, businesses needed to buy a few extra tools, but they were still unlocking value with solutions designed to fill these emerging gaps. Now, companies are forced to manage dozens of tiny pieces that all accomplish tiny parts of a much larger puzzle where certain things overlap and others never do.
While it may seem like a no-brainer to involve more people and more tools and more features, traveling too far down that path means you’re spending money for the sake of access, not the value it provides. Yes, added speed and accessibility are a good thing, but it’s not unheard of for businesses to adopt the modern data stack and become stuck with high costs and long-term debt, leaving no room to scale at the enterprise level.
We’ve seen it happen with traditional cable television crumbling into a pile of separate streaming services that are now starting to resemble the very thing they replaced. For many, the modern data stack has gone too far and created a new problem out of trying to solve a problem that barely existed in the first place.
Building a Smarter Data Stack
There are compelling arguments on both sides of the modern data stack discussion. The fact of the matter is, using a modern data stack is only as effective as your ability to plan and prioritize company needs. The modern data stack is not failed model, but rather one that many businesses have relied too heavily on to solve all their needs by integrating too many moving parts. Avoiding this pitfall means taking proper precautions to build a streamlined an scalable data stack that remains in your control.
When choosing data management integrations you must first identify what your top goals are, and find a solution that addresses them and them alone. It's far too easy to get overwhelmed if you're trying to do a little of everything, so it's best practice to start with the things that really matter, and then expand from there as necessary. Remember, just because you can doesn’t always mean you should!
OneSignal – Actionable Data, Engaged Messaging
Our job is to make your job easy. As the mobile messaging provider for one out of every five apps, we strive to make it as seamless as possible to bring your data into OneSignal, act on it, then bring it back to your CDP or data warehouse.
Alternatively, OneSignal can be used without a data warehouse or a CDP altogether, giving our users the best of both worlds — the ability to get up and running quickly without depending on complex integrations AND a smooth path to connecting with third-party systems when customers are ready.
Our try before you buy model is ideal for ensuring that your data stack functions as desired and provides value before you start spending. We look forward to scaling with you as you grow!
Try OneSignal for Free


